BGP Operations: Aggregation, iBGP, and Route Reflectors
BGP operations extend beyond basic peering into three critical areas: prefix aggregation to control routing table growth, iBGP to propagate external reachability across an autonomous system without leaking it into the IGP, and route reflectors to eliminate the quadratic scaling problem inherent in iBGP full-mesh designs. Together, these mechanisms form the operational backbone of any service provider BGP deployment.
Content
Prefix Aggregation
The Problem: Routing Table Explosion
An autonomous system that owns four contiguous /24 prefixes (192.168.0.0/24 through 192.168.3.0/24) can advertise them individually, placing four entries in every internet router’s table. These prefixes share the first 22 bits, so a single /22 summary covers all four. Multiplied across thousands of networks, aggregation is the primary mechanism keeping the global routing table tractable [7, 8].
Summarization Mechanics
Summarization identifies the longest common bit prefix among a set of routes. For 192.168.0.0/24 through 192.168.3.0/24, the first 22 bits are identical, yielding 192.168.0.0/22. Interior gateway protocols like OSPF and EIGRP perform summarization at area boundaries and automatically suppress the more-specific routes.
The aggregate-address Command
BGP performs aggregation through the aggregate-address command:
router bgp 100
aggregate-address 192.168.0.0 255.255.252.0
Two distinct behaviours control how aggregation interacts with the original prefixes:
- Default (no
summary-only) — BGP advertises both the /22 aggregate and all four contributing /24 specifics [7]. Neighbours receive five routes. The specifics win forwarding decisions via longest-prefix match, while the aggregate serves as a catch-all if any specific is withdrawn. - With
summary-only— BGP suppresses the contributing /24s and advertises only the /22 [7]. Neighbours see a single clean route.
BGP defaults to keeping specifics because it is fundamentally policy-driven [7, 9]. Suppressing specifics can break traffic engineering for downstream autonomous systems that rely on per-prefix path selection.
Aggregation Options
| Option | Purpose |
|---|---|
summary-only | Suppress all contributing specifics; advertise only the aggregate [7] |
as-set | Preserve an unordered set of all contributing AS numbers in the aggregate’s AS_PATH, preventing loops when aggregating routes learned from multiple autonomous systems [1, 7] |
suppress-map | Apply a route-map to selectively suppress individual specifics while advertising others alongside the aggregate [7] |
The as-set option is particularly important in multi-AS aggregation scenarios. Without it, the aggregate’s AS_PATH contains only the aggregating AS, which defeats BGP’s primary loop-prevention mechanism [1].
iBGP: Carrying External Routes Internally
Why Redistribution Fails
When an ASBR learns the full internet routing table (approximately 1 million IPv4 prefixes — May 2026 figure; see CIDR Report) [8] from an eBGP peer, every other router in the AS needs access to those routes for optimal forwarding. Redistributing BGP into the IGP is not viable for two reasons:
- Scale — OSPF and IS-IS were not designed to carry hundreds of thousands of external routes [9, 11]. Link-state databases and SPF calculations would consume unsustainable memory and CPU.
- Lost policy context — BGP path attributes (AS_PATH, LOCAL_PREF, MED, communities) drive intelligent path selection across multiple exit points [1]. IGPs have no equivalent mechanism.
The iBGP Role
iBGP solves this by maintaining a parallel routing plane within the AS:
graph LR subgraph "IGP Plane (OSPF / IS-IS)" direction LR A1["Router A<br/>Loopback: 1.1.1.1"] ---|"metric 10"| B1["Router B<br/>Loopback: 2.2.2.2"] B1 ---|"metric 20"| C1["Router C<br/>Loopback: 3.3.3.3"] end subgraph "iBGP Plane" direction LR A2["ASBR A"] ---|"8.8.8.0/24<br/>next-hop: 1.1.1.1"| B2["Internal"] B2 ---|"8.8.8.0/24<br/>next-hop: 1.1.1.1"| C2["ASBR C"] end
| Plane | Responsibility | Carries |
|---|---|---|
| IGP (OSPF / IS-IS) | Internal reachability: “How do I physically reach the next-hop router?” | Loopbacks, link prefixes, metrics |
| iBGP | External reachability: “Which ASBR knows the best path to 8.8.8.0/24?” | Full internet table, path attributes, policy |
Key Insight
iBGP provides the BGP next-hop; the IGP provides the forwarding path to reach that next-hop. This separation keeps the IGP lean while preserving full BGP policy semantics.
The Full-Mesh Requirement
iBGP enforces a critical loop-prevention rule: a route learned from one iBGP peer must not be re-advertised to another iBGP peer [1, 2]. This is necessary because iBGP peers share the same AS number, so AS_PATH-based loop detection (which works for eBGP) provides no protection [1].
The consequence is that every iBGP speaker must peer directly with every other, forming a full mesh [2]. Session count scales quadratically as n(n-1)/2 [2]:
| Routers | iBGP Sessions |
|---|---|
| 5 | 10 |
| 50 | 1,225 |
| 500 | 124,750 |
For any non-trivial service provider network, a full mesh is operationally impossible to configure, monitor, and troubleshoot.
Route Reflectors
Route reflectors (RRs) eliminate the full-mesh requirement by selectively relaxing the iBGP re-advertisement rule [2]. An RR is authorised to reflect routes received from one iBGP client to other clients and non-client peers [2].
Topology: In a route-reflector design, client routers peer only with the RR rather than with every other router in the AS. A typical deployment places the RR at the hub with client routers (R1, R2, R3, R4) as spokes. This reduces session count from n(n-1)/2 to n [2].
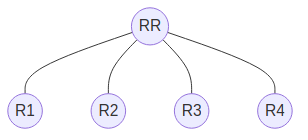
graph TD RR(("RR")) R1(("R1")) R2(("R2")) R3(("R3")) R4(("R4")) RR --- R1 RR --- R2 RR --- R3 RR --- R4
Each client maintains a single iBGP session to the RR instead of peering with every other client.
RR Loop Prevention
Because route reflectors break the standard iBGP re-advertisement rule, they introduce two dedicated attributes for loop detection:
- ORIGINATOR_ID — set to the router ID of the peer that originally injected the route into iBGP [2]. If a router receives a reflected route carrying its own ORIGINATOR_ID, it discards the route [2].
- CLUSTER_LIST — analogous to AS_PATH but operating at the RR cluster level [2]. Each RR appends its cluster ID when reflecting a route. A repeated cluster ID indicates a loop [2].
Redundancy and Real-World Deployment
Production service provider networks deploy at least two route reflectors for resilience [2, 9]. RRs are central to multiple functions beyond basic internet route distribution:
- MPLS VPN route exchange — reflecting VPNv4 and VPNv6 routes between PE routers [5, 6]
- Internet edge distribution — propagating the full table between border routers [9]
- Traffic engineering — centralising path visibility for TE policy decisions
Why iBGP Cannot Replace an IGP
Despite carrying routing information, iBGP is architecturally dependent on an underlying IGP. Five fundamental constraints prevent iBGP from operating as a standalone routing protocol:
- Next-hop resolution dependency — iBGP routes specify a BGP next-hop (typically a loopback address). The IGP must provide the actual forwarding path to reach that next-hop. Without it, every iBGP route is unusable.
- No neighbour discovery — OSPF and IS-IS discover adjacent routers automatically via hello packets. BGP requires explicit manual configuration of every neighbour and has no awareness of physical topology.
- No topology awareness — BGP selects paths based on policy attributes, not link metrics. Without an IGP computing shortest-path forwarding trees, routers cannot determine which interface to use for packet forwarding.
- TCP bootstrap problem — iBGP sessions run over TCP. Establishing a TCP session to a non-directly-connected peer (loopback peering) requires IP reachability that only the IGP can provide — a circular dependency without an IGP in place.
- Convergence speed — BGP uses conservative timers (Cisco defaults: 60-second keepalive, 180-second hold time [11]; RFC 4271 §10 suggests 30 s / 90 s [1]) designed for inter-domain stability, not sub-second failure detection. OSPF paired with BFD detects link failures in milliseconds, which is the minimum acceptable standard for internal forwarding.
graph TD subgraph "Standard SP Design" direction TB IBGP["iBGP + Route Reflectors<br/>(external routes, VPN routes, policy)"] IGP["IS-IS or OSPF Underlay<br/>(topology, fast convergence, next-hop resolution)"] FWD["Forwarding Plane<br/>(MPLS label switching)"] end IBGP -->|"next-hop resolution"| IGP IGP -->|"label paths"| FWD
iBGP Cannot Replace an IGP
iBGP depends on the IGP for next-hop resolution, has no neighbor discovery, no topology awareness, suffers a TCP bootstrap problem on non-connected peers, and uses conservative timers (Cisco default 60 s keepalive / 180 s hold [11]; RFC 4271 §10 suggests 30 s / 90 s [1]) unsuitable for sub-second failure detection.
References
- RFC 4271 — A Border Gateway Protocol 4 (BGP-4). IETF, January 2006. https://www.rfc-editor.org/rfc/rfc4271
- RFC 4456 — BGP Route Reflection — An Alternative to Full Mesh Internal BGP (IBGP). T. Bates et al., IETF, April 2006. https://www.rfc-editor.org/rfc/rfc4456
- RFC 5065 — Autonomous System Confederations for BGP. P. Traina, D. McPherson, J. Scudder, IETF, August 2007. https://www.rfc-editor.org/rfc/rfc5065
- RFC 7911 — Advertisement of Multiple Paths in BGP (ADD-PATH). D. Walton et al., IETF, July 2016. https://www.rfc-editor.org/rfc/rfc7911
- RFC 4760 — Multiprotocol Extensions for BGP-4. T. Bates et al., IETF, January 2007. https://www.rfc-editor.org/rfc/rfc4760
- RFC 4364 — BGP/MPLS IP Virtual Private Networks (VPNs). E. Rosen, Y. Rekhter, IETF, February 2006. https://www.rfc-editor.org/rfc/rfc4364
- Cisco — Understand Route Aggregation in BGP (Doc 5441). https://www.cisco.com/c/en/us/support/docs/ip/border-gateway-protocol-bgp/5441-aggregation.html
- CIDR Report — Active BGP entries (FIB). https://www.cidr-report.org/as2.0/
- S. Halabi, Internet Routing Architectures, 2nd ed., Cisco Press, 2000.
- I. Pepelnjak, J. Guichard, MPLS and VPN Architectures, Cisco Press, 2000.
- J. Doyle & J. Carroll, Routing TCP/IP, Volume II, 2nd ed., Cisco Press, 2016.